本文最后更新于:2024年6月28日 中午
Kafka Stream 基本使用
Apache Kafka Streams 是一款强大的实时流处理库,为构建实时数据处理应用提供了灵活且高性能的解决方案。
Kafka Streams 是 Apache Kafka 生态系统中的一部分,它不仅简化了流处理应用的构建,还提供了强大的功能,如事件时间处理、状态管理、交互式查询等。其核心理念是将流处理与事件日志结合,使应用程序能够实时处理数据流。
1. 前言
由于公司需开发数据清洗服务,而且需要实时性高的数据处理,结合线上数据是输出到kafka,故采用 Kafka Streams 来作为数据清洗服务开发,本编结合一个demo,讲述 Kafka Streams 的基本使用。
Kafka Streams的特点:
- 设计为一个简单而轻量级的客户端库,可以很容易地嵌入到任何 Java 应用程序中,并与用户为其流应用程序提供的任何现有打包、部署和操作工具集成。
- 除了 Apache Kafka 本身作为内部消息传递层之外,对系统没有外部依赖关系;值得注意的是,它使用 Kafka 的分区模型来水平扩展处理,同时保持强大的排序保证。
- 支持容错本地状态,从而实现非常快速高效的有状态操作,如窗口联接和聚合。
- 支持 exact-once 处理语义,以保证每条记录将只处理一次,即使 Streams 客户端或 Kafka 代理在处理过程中出现故障也是如此。
- 采用一次一条记录的处理来实现毫秒级处理延迟,并支持基于事件时间的窗口化操作,以及记录的无序到达。
- 提供必要的流处理基元,以及高级流 DSL 和低级处理器 API。
2. 核心概念
- Stream: 一个无限的、有序的、可重放的、并且可失败的数据记录序列。在Kafka中,一个流可以看作是一个或多个Kafka主题的消息记录。
- Stream Processor: 流处理器是对流数据进行处理的逻辑单元。它可以是一个简单的消息转换(例如,增加数据的时间戳),也可以是一个复杂的,如聚合或连接多个流。
- Topologies: 流处理拓扑是构成流处理程序的逻辑流程。一个拓扑是由多个处理器节点(处理器和转换器)和源节点(用于读取流数据)和汇节点(用于输出处理后的数据)组成的。
- KStream: 主要代表一种记录流,其中每个数据记录代表一个独立的数据实体。
- KTable: 表示一个更新流,每个数据记录表示一个表中的行。在更新流中,具有相同键的数据记录会覆盖先前的记录,类似于传统数据库的更新操作。
- Global KTable: 与KTable类似,但在所有应用程序实例中都全局可用,并且是只读的。
- State Stores: 本地存储,用于存储中间处理状态。状态存储可以是持久化的也可以是非持久化的。它们使得流处理器可以提供有状态的操作。
- Windowing: 用于将无限的数据流分成有限的块进行处理。窗口可以是时间驱动的(如固定时间窗口、滑动时间窗口)或基于数据记录数的。
- Processor API: 一个低级别的,允许开发人员定义和连接自定义处理器的API。使用该API,开发人员可以控制数据的流动和事件处理的精细细节。
- DSL (Domain Specific Language): 高级流DSL是一个构建流处理拓扑的表达式式的API。它提供了一套简单的操作符用于过滤、映射、聚合等操作。
详细介绍请查看官方文档:https://kafka.apache.org/37/documentation/streams/core-concepts
3. 基本用法
本例结合官方文档中的示例,输入文本计算单词,用于处理无限的数据流,统计出单词数量输出。
Demo 仓库地址:https://github.com/Gumengyo/kafka-stream-demo

引入依赖:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
| <dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-streams</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.kafka</groupId>
<artifactId>spring-kafka</artifactId>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<optional>true</optional>
</dependency>
|
创建Topic:
1
2
3
| ./kafka-topics.sh --create --bootstrap-server localhost:9092 --topic streams-plaintext-input --replication-factor 1 --partitions 1
./kafka-topics.sh --create --bootstrap-server localhost:9092 --topic streams-wordcount-output --replication-factor 1 --partitions 1
|
3.1 结合Spring框架构建Kafka Streams
- 配置文件
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
| server:
port: 9991
spring:
application:
name: kafka-demo
kafka:
bootstrap-servers: localhost:9092
producer:
retries: 10
key-serializer: org.apache.kafka.common.serialization.StringSerializer
value-serializer: org.apache.kafka.common.serialization.StringSerializer
compression-type: lz4
consumer:
group-id: ${spring.application.name}-test
key-deserializer: org.apache.kafka.common.serialization.StringDeserializer
value-deserializer: org.apache.kafka.common.serialization.StringDeserializer
kafka:
hosts: localhost:9092
group: ${spring.application.name}
|
- 配置 Kafka Streams
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
| @Setter
@Getter
@Configuration
@EnableKafkaStreams
@ConfigurationProperties(prefix="kafka")
public class KafkaStreamConfig {
private static final int MAX_MESSAGE_SIZE = 16* 1024 * 1024;
private String hosts;
private String group;
@Bean(name = KafkaStreamsDefaultConfiguration.DEFAULT_STREAMS_CONFIG_BEAN_NAME)
public KafkaStreamsConfiguration defaultKafkaStreamsConfig() {
Map<String, Object> props = new HashMap<>();
props.put(StreamsConfig.BOOTSTRAP_SERVERS_CONFIG, hosts);
props.put(StreamsConfig.APPLICATION_ID_CONFIG, this.getGroup()+"_stream_aid");
props.put(StreamsConfig.CLIENT_ID_CONFIG, this.getGroup()+"_stream_cid");
props.put(StreamsConfig.RETRIES_CONFIG, 10);
props.put(StreamsConfig.DEFAULT_KEY_SERDE_CLASS_CONFIG, Serdes.String().getClass());
props.put(StreamsConfig.DEFAULT_VALUE_SERDE_CLASS_CONFIG, Serdes.String().getClass());
return new KafkaStreamsConfiguration(props);
}
}
|
- 常量
1
2
3
4
5
6
| public class KafkaConstants {
public static final String BOOTSTRAP_SERVERS = "localhost:9092";
public static final String INPUT_TOPIC = "streams-plaintext-input";
public static final String OUTPUT_TOPIC = "streams-wordcount-output";
}
|
- 创建 KStream
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
| @Configuration
@Slf4j
public class KafkaStreamHelloListener {
@Bean
public KStream<String,String> kStream(StreamsBuilder streamsBuilder){
KStream<String, String> stream = streamsBuilder.stream(KafkaConstants.INPUT_TOPIC);
stream.flatMapValues(new ValueMapper<String, Iterable<String>>() {
@Override
public Iterable<String> apply(String value) {
return Arrays.asList(value.split(" "));
}
})
.groupBy((key,value)->value)
.windowedBy(TimeWindows.of(Duration.ofSeconds(1)))
.count()
.toStream()
.map((key,value)->{
System.out.println("key:"+key+",value:"+value);
return new KeyValue<>(key.key().toString(),value.toString());
})
.to(KafkaConstants.OUTPUT_TOPIC);
return stream;
}
}
|
3.2 自定义配置构建 Kafka Streams
将Demo中 KafkaStreamConfig.java 和 KafkaStreamHelloListener.java 注释掉,
在 SpringBootTest 添加下面代码:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
| @SpringBootTest
class KafkaStreamDemoApplicationTests {
@Value("${kafka.hosts}")
private String hosts;
@Value("${kafka.group}")
private String group;
@Test
void testCreateKStream() throws InterruptedException {
Properties props = new Properties();
props.put(StreamsConfig.APPLICATION_ID_CONFIG, this.group + "_stream_aid");
props.put(StreamsConfig.CLIENT_ID_CONFIG, this.group + "_stream_cid");
props.put(StreamsConfig.BOOTSTRAP_SERVERS_CONFIG, hosts);
props.put(StreamsConfig.RETRIES_CONFIG, 10);
props.put(StreamsConfig.DEFAULT_KEY_SERDE_CLASS_CONFIG, Serdes.String().getClass());
props.put(StreamsConfig.DEFAULT_VALUE_SERDE_CLASS_CONFIG, Serdes.String().getClass());
props.put(StreamsConfig.NUM_STREAM_THREADS_CONFIG, 2);
StreamsBuilder streamsBuilder = new StreamsBuilder();
KStream<String, String> stream = streamsBuilder.stream(KafkaConstants.INPUT_TOPIC);
stream.flatMapValues((ValueMapper<String, Iterable<String>>) value -> Arrays.asList(value.split(" ")))
.groupBy((key,value)->value)
.windowedBy(TimeWindows.of(Duration.ofSeconds(1)))
.count()
.toStream()
.map((key,value)->{
System.out.println("key:"+key+",value:"+value);
return new KeyValue<>(key.key().toString(),value.toString());
})
.to(KafkaConstants.OUTPUT_TOPIC);
new CountDownLatch(1).await();
}
}
|
3.3 测试
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
| public class ProducerQuickStart {
public static void main(String[] args) {
Properties prop = new Properties();
prop.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, KafkaConstants.BOOTSTRAP_SERVERS);
prop.put(ProducerConfig.RETRIES_CONFIG, 5);
prop.put(ProducerConfig.COMPRESSION_TYPE_CONFIG,"lz4");
prop.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringSerializer");
prop.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringSerializer");
KafkaProducer<String, String> producer = new KafkaProducer<String, String>(prop);
ProducerRecord<String, String> producerRecord1 = new ProducerRecord<String, String>(KafkaConstants.INPUT_TOPIC, "key_001", "hello kafka");
ProducerRecord<String, String> producerRecord2 = new ProducerRecord<String, String>(KafkaConstants.INPUT_TOPIC, "key_002", "hello world");
producer.send(producerRecord1);
producer.send(producerRecord2);
producer.close();
}
}
|
执行上面main方法测试发送消息:
hello kafka
hello world
查看kafka 内消息:

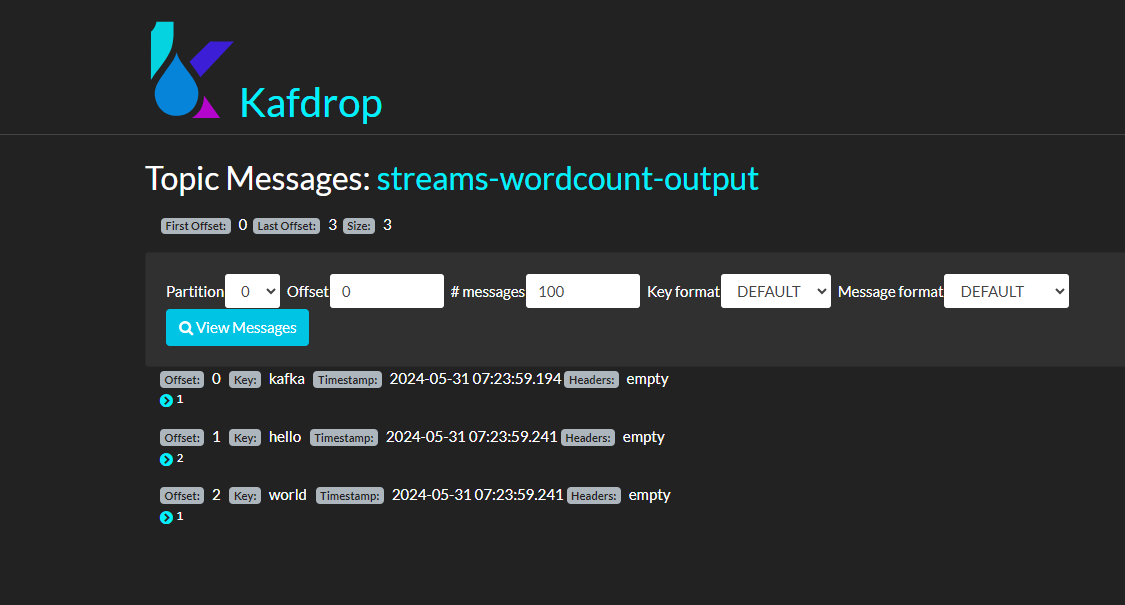
可以看到已经正确统计单词结果,输出到topic 为 streams-wordcount-output 中
参考

